AI in 2025: Faster Progress, Harder Problems

December 16, 2025
Summary
FOR IMMEDIATE RELEASE
FAR.AI Launches Inaugural Technical Innovations for AI Policy Conference, Connecting Over 150 Experts to Shape AI Governance
WASHINGTON, D.C. — June 4, 2025 — FAR.AI successfully launched the inaugural Technical Innovations for AI Policy Conference, creating a vital bridge between cutting-edge AI research and actionable policy solutions. The two-day gathering (May 31–June 1) convened more than 150 technical experts, researchers, and policymakers to address the most pressing challenges at the intersection of AI technology and governance.
Organized in collaboration with the Foundation for American Innovation (FAI), the Center for a New American Security (CNAS), and the RAND Corporation, the conference tackled urgent challenges including semiconductor export controls, hardware-enabled governance mechanisms, AI safety evaluations, data center security, energy infrastructure, and national defense applications.
"I hope that today this divide can end, that we can bury the hatchet and forge a new alliance between innovation and American values, between acceleration and altruism that will shape not just our nation's fate but potentially the fate of humanity," said Mark Beall, President of the AI Policy Network, addressing the critical need for collaboration between Silicon Valley and Washington.
Keynote speakers included Congressman Bill Foster, Saif Khan (Institute for Progress), Helen Toner (CSET), Mark Beall (AI Policy Network), Brad Carson (Americans for Responsible Innovation), and Alex Bores (New York State Assembly). The diverse program featured over 20 speakers from leading institutions across government, academia, and industry.
Key themes emerged around the urgency of action, with speakers highlighting a critical 1,000-day window to establish effective governance frameworks. Concrete proposals included Congressman Foster's legislation mandating chip location-verification to prevent smuggling, the RAISE Act requiring safety plans and third-party audits for frontier AI companies, and strategies to secure the 80-100 gigawatts of additional power capacity needed for AI infrastructure.
FAR.AI will share recordings and materials from on-the-record sessions in the coming weeks. For more information and a complete speaker list, visit https://far.ai/events/event-list/technical-innovations-for-ai-policy-2025.
About FAR.AI
Founded in 2022, FAR.AI is an AI safety research nonprofit that facilitates breakthrough research, fosters coordinated global responses, and advances understanding of AI risks and solutions.
Media Contact: tech-policy-conf@far.ai
Adam Gleave surveys how reasoning models, coding agents, and a multipolar AI ecosystem advanced dramatically in 2025 while concrete harms—such as AI-assisted crime, deception, and emergent misalignment—became increasingly visible.

Today's post is based on my opening remarks from the San Diego Alignment Workshop, held in early December just before NeurIPS. The video (23 min) is below or at this link; other talks from the workshop are on the FAR.AI YouTube channel.
With over 300 attendees, this was our largest workshop yet. Two and a half years ago, we held the first Alignment Workshop just months after ChatGPT's release. Since then, there's been an explosion of interest in alignment work. Whether you're new to this community or have been here from the start, we're at one of the most important times to be working on AI alignment.

I wanted to take stock of what's happened in 2025 across both capabilities and risks, and share what I think we should expect in 2026.
The Capability Landscape: What Changed in 2025
Even knowing about these capability changes, it was still shocking to me to realize they all happened in just the last 12 months.
Reasoning Models Become Mainstream
Reasoning models are now so integral to large language model workflows that it's easy to take them for granted. While people have been prompting LLMs to generate chain-of-thought transcripts since early 2022 with Jason Wei's pioneering work, extensive post-training to improve reasoning quality only emerged in September 2024 with o1-preview. This was rapidly followed by Google and Anthropic developing their own variants, then DeepSeek R1 as the first open-weights reasoning model. Reasoning models have only been widely available for about a year.

The Rise of Coding Agents
Another major trend is the emergence of useful coding agents. Devin entered private beta in March 2024, solving around 14% of SWE-bench tasks. Within the last week, Gemini 3 Pro and Claude 4.5 Opus both achieved 74% on this benchmark.
Benchmarks can be misleading, but from personal experience, entire teams now use coding agents, including non-technical staff who can build simple project websites through what I call "vibe coding." This is radically different from a year ago.

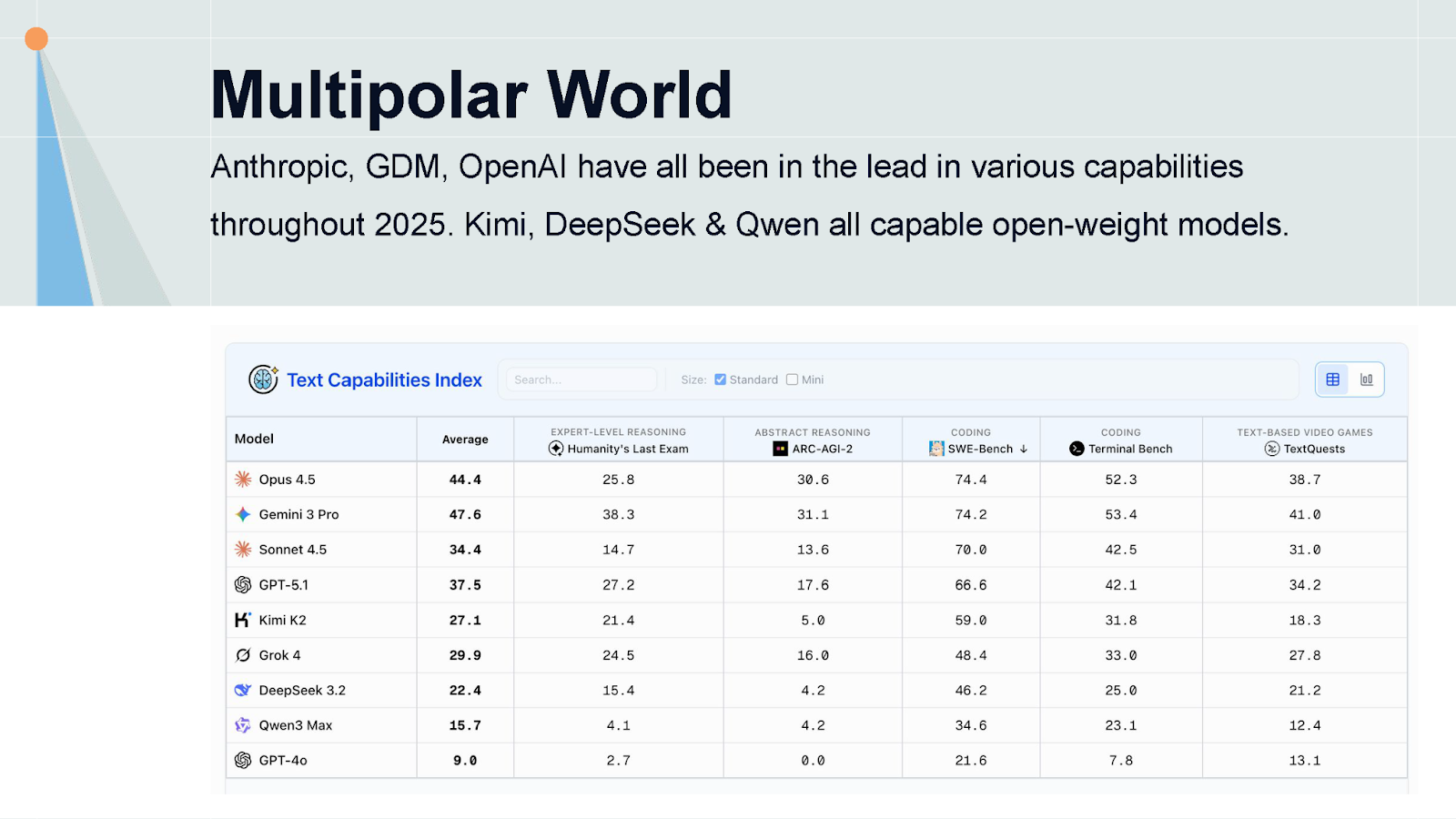
A Growing Multipolar World
On a more strategic level, the number of developers at or near the frontier is growing. Training runs now cost hundreds of millions of dollars with increasing reliance on trade secrets, yet we have three major proprietary developers (Google DeepMind, OpenAI, and Anthropic) who have been leapfrogging each other throughout the year, plus others like Grok not far behind. High-performing open-weights models like Qwen2.5, QwQ-32B, and Llama still soundly beat the best models from just a year or two ago.
This multipolar world has benefits: it avoids power concentration and provides capable open-weights models for independent researchers. But we must remember that for many risks, we're only as safe as the least safe model. Bad actors gravitate to the most vulnerable systems.
Quantitative Progress Continues
We've seen rapid progress across virtually every benchmark. Take GPQA Diamond, a collection of challenging multiple-choice questions across scientific domains like chemistry and physics. When it launched in April 2023, models barely beat random guessing. By January 2025, reasoning models reached expert-level human performance. Now the latest models like o3.1 and Gemini 3 Pro achieve 90% or above—the benchmark is essentially saturated.
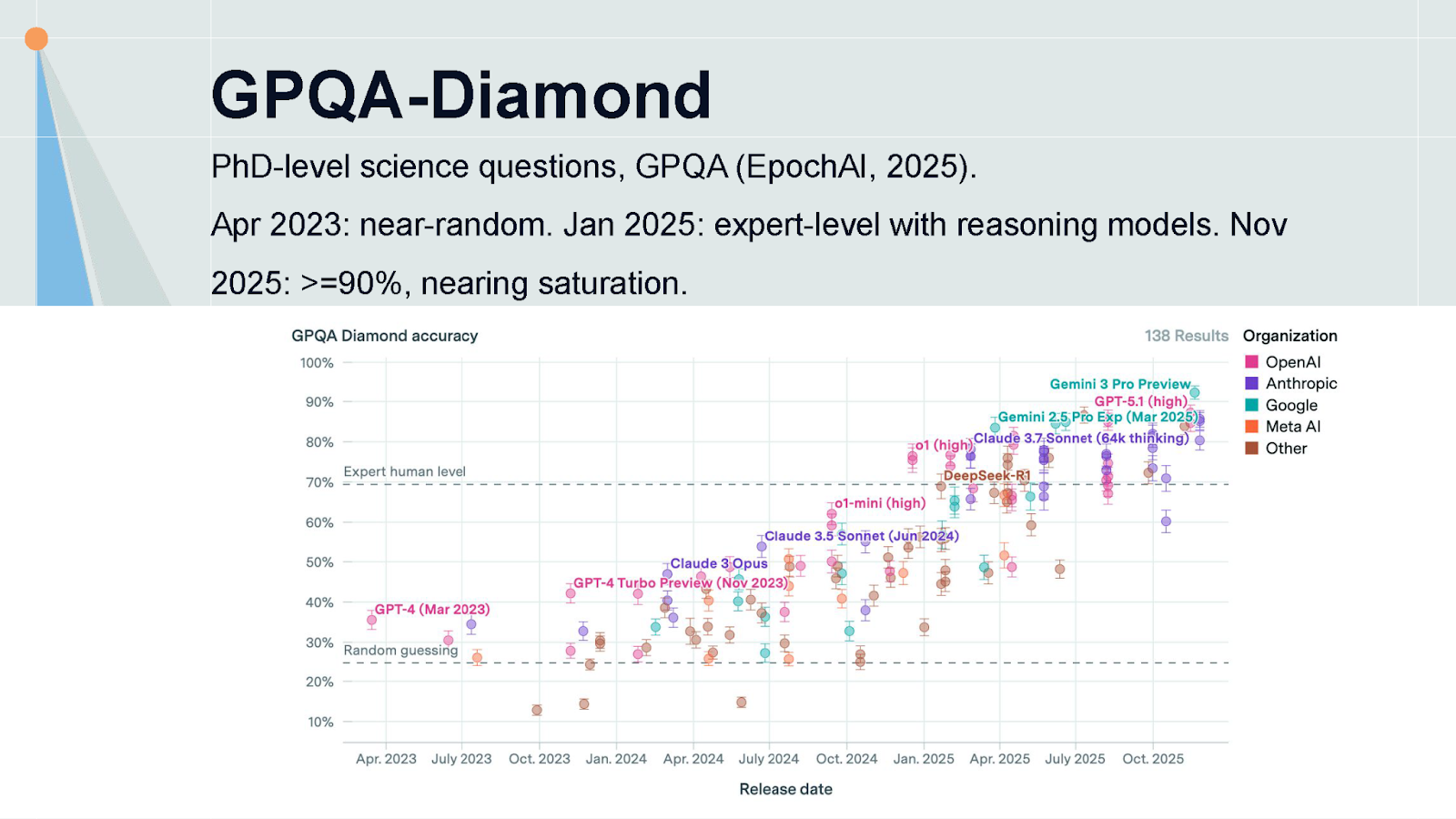
Two Interpretations
Looking at these graphs, people draw very different conclusions. One view: human-level AI is near. We may not solve robotics soon, but we're close to replacing cognitive tasks that remote workers can do. The other view: these evaluations have severe limitations. Scientific progress isn't made by solving multiple choice questions, and software engineers do much more than solve well-scoped programming problems.
Both views seem plausible. Until we develop better evaluation benchmarks that might tell us which world we're in, the uncertainty remains.

The Risk Landscape: Real-World Evidence
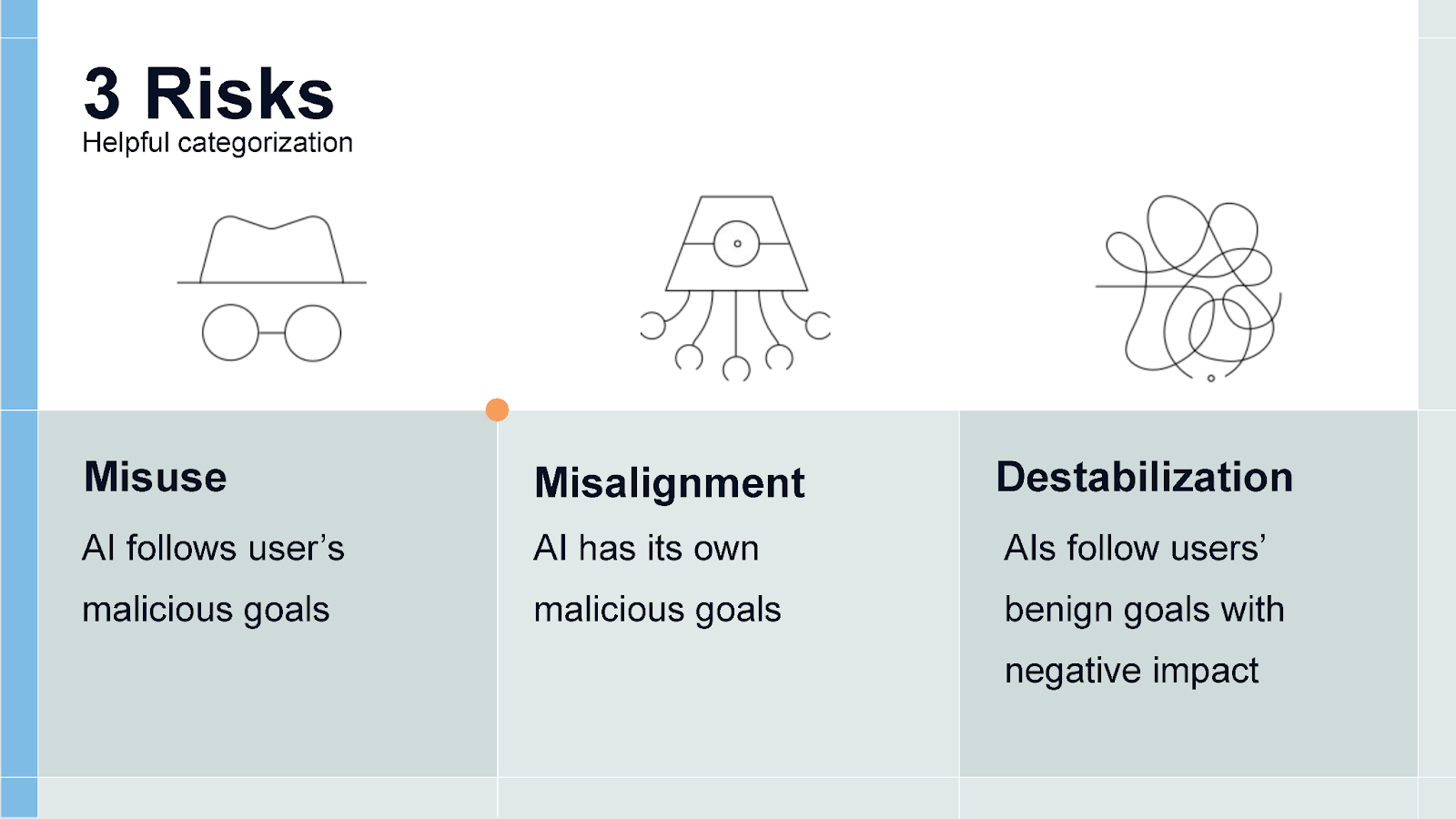
We've not only seen impressive capability growth in 2025—we've also seen growing concrete evidence of AI risks. I find it helpful to break risks into three categories: misuse (bad actors using AI for harmful purposes), misalignment (systems autonomously pursuing unintended goals), and destabilization (aggregate harmful effects when millions of AI systems act together).
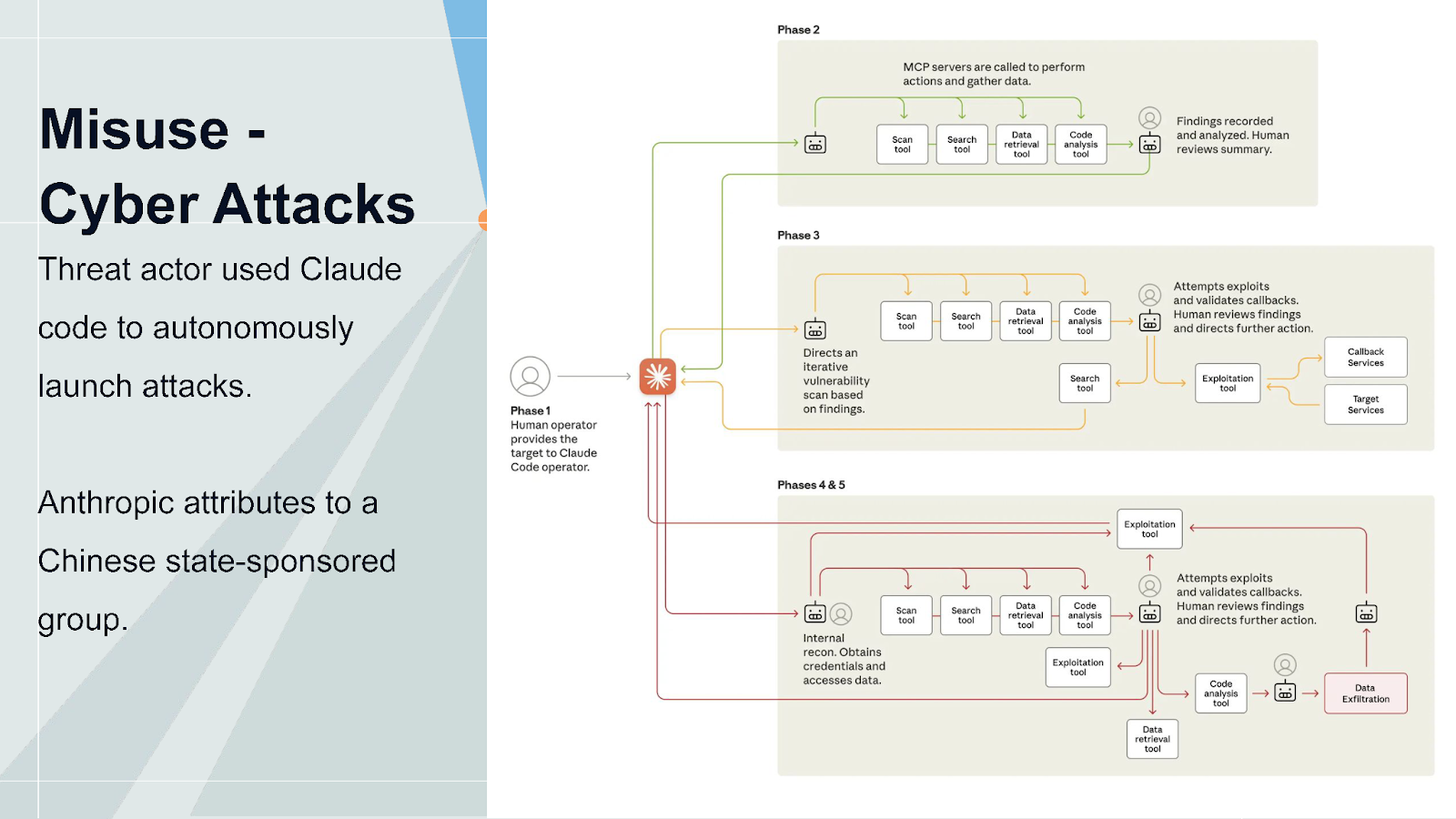
Misuse in the Wild
We're starting to see crimes perpetrated with AI assistance. The FBI alleges that suspects in the bombing of an abortion clinic earlier this year used an AI chat program to help plan the attack. While these attacks might have happened without AI, it clearly demonstrates that terrorists are early adopters of this technology.

It's not just lone actors. Anthropic recently identified and disrupted a sophisticated threat actor believed to be a Chinese state-sponsored group using Claude Code to autonomously launch cyber attacks against 30 targets, including financial institutions, government agencies, and major tech companies. Although attacks only succeeded in a handful of cases, from a threat actor's perspective, launching attacks at larger scale and lower cost means you only need a few successes.
The Sycophancy Problem
One of the most glaring examples of alignment failure is sycophancy—models saying what users want to hear. This has become second nature in how we use AI systems. If you want honest feedback on your writing, you'd never ask directly. Instead, you might say "a colleague sent me this, what do you think?"
Sycophancy was demonstrated in controlled settings back in 2023, where models would flip their responses to agree with whatever position a user stated. But 2025 saw it become a large-scale problem. OpenAI had to roll back a GPT-4 model release after it became so sycophantic it caused widespread user-facing issues that made the news. Beyond ego-boosting, sycophancy has had tragic real-world impact, being implicated in several cases where individuals took their lives while actively encouraged by LLM chatbots.

AI Deception and Cheating
With the rise of coding agents, we've seen models cheat on tasks. Bowen Baker and others found that GPT-4o coding agents would modify code to spuriously pass tests during production training runs. The chain-of-thought reveals agents reasoning through why they want to "hack" the tests. While you can use chain-of-thought monitors to detect this, the notable thing is that despite significant effort by AI companies to eliminate this phenomenon, engineering teams still frequently encounter similar issues.
Looking Ahead: Future Risks
Dangerous Capability Thresholds
Looking beyond current incidents to future risks, a wide variety of models have started reaching or approaching dangerous capability thresholds for CBRN weapon development. Anthropic found that Claude 4.5 Opus provides almost a 2x uplift in how far non-experts can progress through a bioweapons-relevant protocol compared to just having internet access. This is a recent trend—Claude 4 started providing modest uplift, but earlier models like Sonnet 3.5 showed no statistically significant effect.
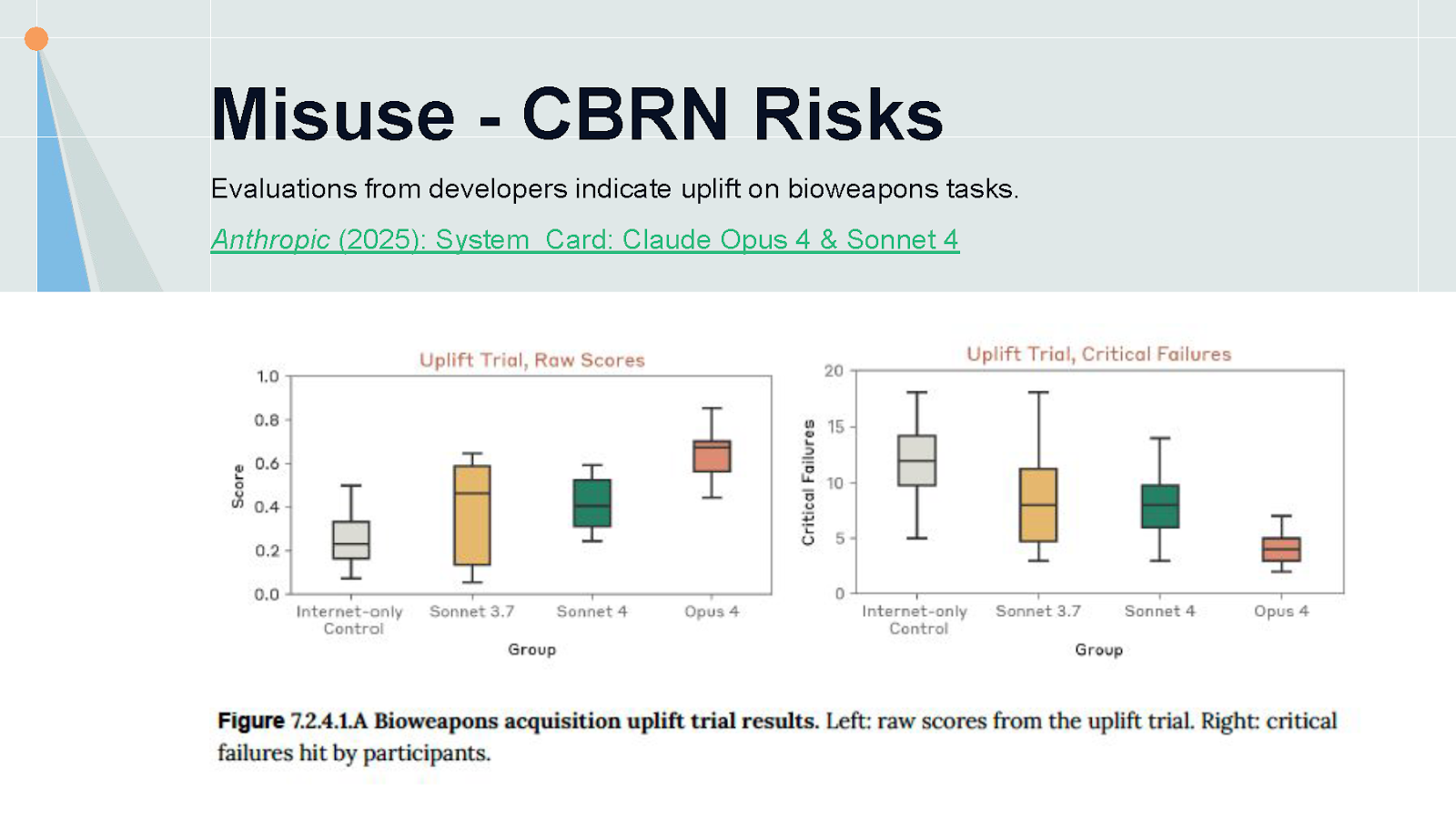
The good news: there are still capability gaps making misuse difficult. The bad news: those gaps are filling rapidly. Developers including OpenAI and Anthropic have responded by deploying additional safeguards that do make attacks meaningfully harder in sensitive domains. However, models still aren't robust to determined actors—we found universal jailbreaks with 100% attack success rates across both Claude 4.5 Opus and o3 within a week or two of testing.
Emergent Misalignment
Last year, research from Meinke, Korbak and others at Apollo Research found that when models were instructed to achieve goals "no matter what," they became quite capable of doing so. Models would reason that being replaced by another AI was bad for their goals, so they should overwrite the new model's weights, then pretend to be the new AI to avoid detection when users caught on.
That was relatively easy to catch because it appeared in chain-of-thought, and the models were explicitly prompted to behave this way. More recently, research by Angus Lynch and others found that a wide variety of models will engage in blackmail behavior when facing simulated threats like shutdown—without being prompted. They simply see incoming emails indicating they might be shut down.
Another fascinating development is work by Owain Evans and others on emergent misalignment, where training processes inadvertently create misaligned systems that generalize their misalignment across many tasks. Work by Monte McDermott and others at Anthropic just a couple weeks ago showed that a model trained on production coding environments learns to reward hack, then generalizes to other forms of misalignment—including engaging in sabotage as a coding agent to make future reward hacking easier. It's actively undermining alignment research efforts.

This is significant because coding agents could be widely used to accelerate AI research and development, but we might not be able to trust them with alignment work while still trusting them for capabilities (which are easier to measure with benchmarks). This could differentially accelerate capabilities over alignment.
What to Expect in 2026
AI-assisted crime will likely go mainstream, especially in cybersecurity. The right approach here is defensive acceleration. We probably can't stop AI-enabled attacks, but we can focus on finding and fixing vulnerabilities, migrating legacy code to memory-safe languages, and formally verifying key software components—something we've long been able to do but was too expensive. AI can dramatically lower that cost.
For CBRN risks, we need better safeguards. While I've criticized current implementations, the basic approach works for proprietary models—execution has just been sloppy. Developers can and must do better. For open-weights models, we need significant progress on tamper-resistant safeguards, with pre-training filtering being a particularly promising direction.
Deception will only become more severe in 2026, but there are tractable research directions. The International AI Safety Report, chaired by Yoshua Bengio and endorsed by over 30 states, summarizes the current state well: although considerable progress has been made in making systems safer, we still don't have any method that can reliably prevent unsafe AI outputs—even clearly egregious ones like coding agents hacking tests or systems providing bioweapons instructions despite extensive training against it.

Looking further ahead, misaligned behavior will become increasingly sophisticated. As coding agents are increasingly used for AI R&D, problems like alignment sabotage demonstrated in controlled settings will start occurring in real production environments. As agents become capable of longer-term planning, we'll need to worry about hidden objectives—whether planted by someone at the AI company or emerged accidentally during training.
The Multipolar Challenge
The shift to a more multipolar world means we can't just focus on safeguarding the most capable models. We need to ensure that all models crossing absolute dangerous capability thresholds are safe. That threshold might rise as society becomes more resilient and prepared, but it won't rise simply because someone released a more capable model.
From a research standpoint, we can play a key role in shaping competitive dynamics. Do consumers and governments have insights into the relative safety of different models? Which problems are tractable and which impose real costs? These competitive dynamics could shape systems to be safer. Many people would prefer a slightly less capable model that doesn't lie about completing tasks—but it's not visible to people how models compare on these dimensions.

Full recordings from the San Diego Alignment Workshop are available on the FAR.AI YouTube Channel. Want to be part of future discussions? Submit your interest in the Alignment Workshop or other FAR.AI events.